
vLLM + LMCache: corré KV cache reuse sin GPU
Guia didactica para desarrollar vLLM + LMCache end-to-end desde una laptop, sin GPU. Que resuelve, como montarlo y como contribuir.
Bajar la barrera: de la GPU dedicada a la memoria unificada
Existe un mito instalado: que para tocar la infraestructura de inferencia de LLMs necesitas si o si una GPU dedicada cara con CUDA. La realidad es mas matizada. El framework multiplataforma de LMCache desacoplo la GPU de la mayoria de los caminos de datos del core.
Ojo: esto no significa que sea gratis. Sigue habiendo un costo de hardware muy real (la RAM de tu maquina, o el precio de un equipo con memoria unificada). Lo que cambia es la barrera de entrada: ya no necesitas una GPU NVIDIA dedicada para empezar a desarrollar y validar. Te alcanza con una MacBook (Apple Silicon) o un equipo Linux con CPU para correr el pipeline completo de vLLM + LMCache de punta a punta: modificar codigo, correr tests y validar end-to-end.
En este post te explicamos que problema resuelve LMCache, por que tu laptop alcanza, el rol clave de la memoria unificada, como montarlo y como hacer tu primer aporte.
Que problema resuelve LMCache
¿Que es el KV cache? Cuando un LLM genera texto, procesa los tokens (las palabras) usando un mecanismo de atencion que, para cada token, calcula dos vectores: una Key (K) y un Value (V) — de ahi el nombre "KV". Para generar el siguiente token, el modelo necesita los K y V de todos los tokens anteriores. En vez de recalcularlos cada vez (carisimo), se guardan en una memoria temporal: el KV cache. Es, basicamente, la "memoria de trabajo" del modelo mientras escribe una respuesta.
Durante la inferencia de un LLM, cada request calcula un segmento de KV cache que sostiene la generacion de los siguientes tokens. El detalle clave: si varios contextos comparten un prefijo comun (un system prompt, un documento recuperado por RAG —Retrieval-Augmented Generation, cuando el modelo recibe texto externo como contexto—, un dialogo multi-turno), ese KV que normalmente se recalcularia se puede reusar directamente desde otro request, otra maquina o desde disco.
LMCache es un motor de KV cache independiente. Su trabajo es:
- Recibir el KV del engine de inferencia (vLLM, SGLang, etc.)
- Agregarlo en memoria (capa L1)
- Persistirlo en almacenamiento externo (L2: disco, Redis, object storage, NIXL)
- Devolver el KV que matchea cuando llega un request nuevo
Para la capa de arriba es simplemente una "capa de cache + coordinacion multi-maquina". En escenarios con alta reutilizacion puede recortar el time-to-first-token (TTFT) en un orden de magnitud.
Visto en un diagrama, asi se ubica LMCache entre el engine y el almacenamiento:
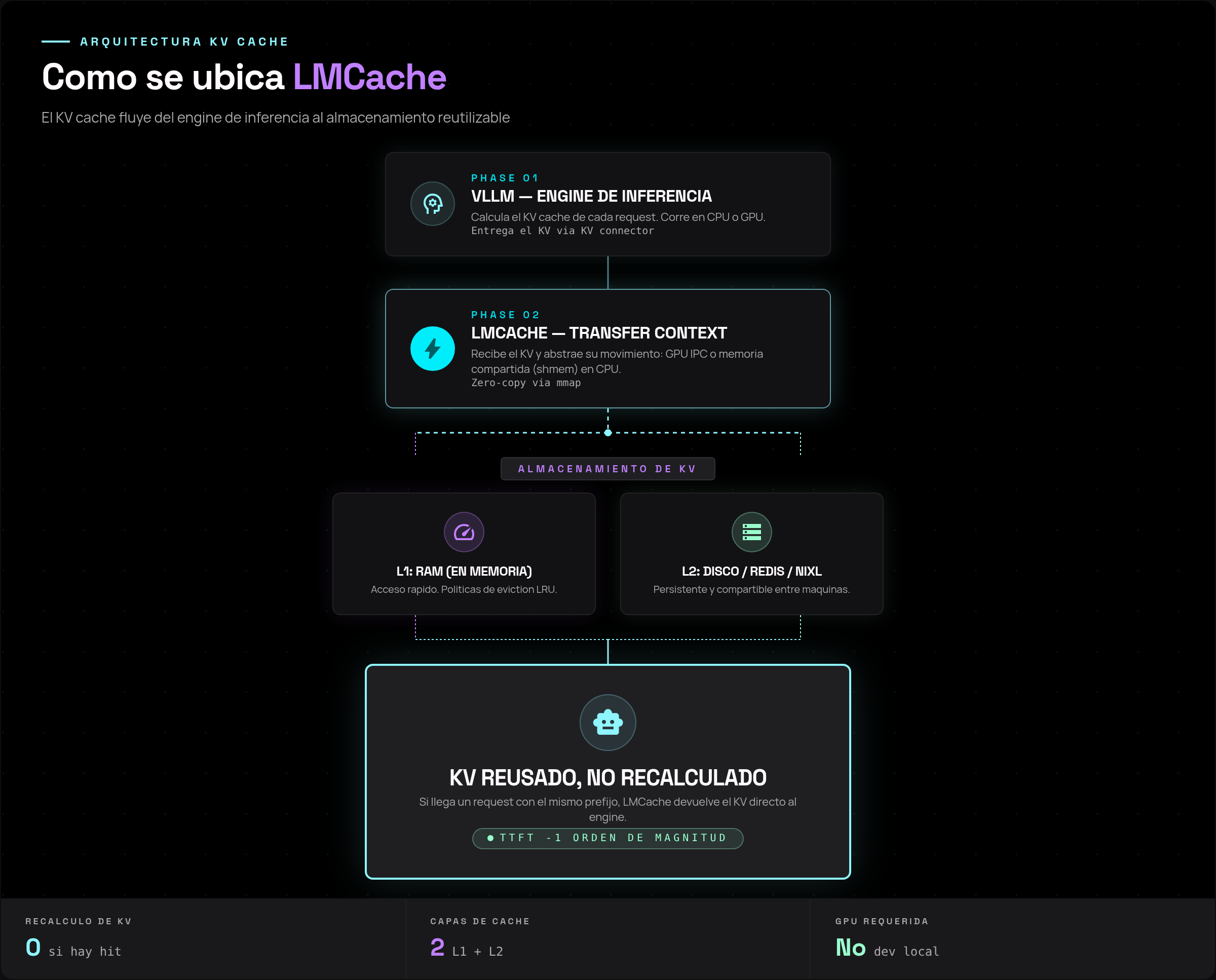
El KV nunca tiene que recalcularse mientras siga vivo en L1 o L2: cuando llega un request con el mismo prefijo, LMCache lo devuelve directo al engine.
La idea para recordar: la estructura de datos central de LMCache es el tensor, y la forma de moverlo se abstrae en un "Transfer Context". Ese contexto puede viajar por GPU IPC o por memoria compartida del CPU. Por eso mismo una MacBook puede correr todo el pipeline.
Por que una laptop alcanza
El codebase de LMCache tiene una capa de abstraccion Platform/Device que centraliza los chequeos especificos del hardware ("hay CUDA disponible?", "existe esta operacion en PyTorch?") detras de pocos puntos de entrada bien definidos.
Para la gran mayoria de los modulos (Frontend, Eviction, Storage, Observability) el procesamiento real de tensores ocurre del lado de Python, y el movimiento de datos queda escondido detras del Transfer Context. Resultado: podes trabajar directo en una laptop, incluso sin acceso a una GPU.
Hay dos tipos de Transfer Context:
- EngineDrivenTransferContext — el worker junta los tensores y envia el payload completo al servidor de LMCache, que lo copia a su pool con
memcpy. Para desarrollo local se recomienda fijar este modo (engine_driven), asi tu pipeline local es equivalente, en cuanto a camino de datos, al de produccion con GPU. - LMCacheDrivenTransferContext — el servidor accede directamente a la memoria del tensor que tiene el worker via un handle IPC (CUDA IPC en GPU, un segmento de memoria compartida POSIX en CPU). Ambos procesos mapean las mismas paginas con
mmap: zero-copy.
El rol de la memoria unificada
Aca esta la pieza que cambia todo, y conviene entenderla bien.
En una PC tradicional, la memoria esta partida en dos pozos separados: la RAM del sistema (para la CPU) y la VRAM (memoria dedicada soldada a la placa de video, para la GPU). No se comparten: cada vez que un dato tiene que pasar de una a la otra, cruza el bus PCIe. Para un LLM eso es un cuello de botella, porque el modelo necesita tener todo su set de parametros en memoria rapida durante la inferencia. Una NVIDIA RTX 4090, la GPU de consumo top, tiene 24 GB de VRAM: ese es el techo. Un modelo mas grande "se derrama" a la RAM del sistema, cruza el PCIe una y otra vez, y se vuelve lentisimo.
La memoria unificada elimina esa division. En Apple Silicon no hay VRAM ni RAM por separado: hay un solo pool de memoria, fisicamente en el mismo chip que la CPU, la GPU y el Neural Engine, accesible a velocidad completa por todos a la vez y sin copias por PCIe. Cuando una Mac con 48 GB corre un modelo, el modelo dispone de esos 48 GB completos.
Y hay un detalle clave que sorprende a mucha gente: en inferencia, lo que define la velocidad (los tokens por segundo) no es el computo bruto, sino el ancho de banda de memoria. Para generar cada token, el hardware tiene que leer todo el set de pesos del modelo; que tan rapido pueda leerlos es lo que marca el ritmo. Algunos numeros de referencia (Apple, via Seresa):
- M4 Pro: 273 GB/s — corre un modelo de 32B (cuantizado: con los pesos comprimidos a menos bits para ocupar menos memoria) a ~12 tokens/s
- M4 Max: 546 GB/s — aproximadamente el doble
- NVIDIA H100 (datacenter): 3,35 TB/s — mucho mas rapido, pero arranca en USD 30.000+ y necesita infraestructura de datacenter
Por eso una Mac es hoy una de las plataformas mas eficientes para inferencia local: la simplicidad de un solo pool de memoria, sin VRAM que se quede corta.
Pero "sin GPU" no quiere decir "sin costo"
Importante ser honestos: esta arquitectura abre la posibilidad, no la regala. El costo del hardware es muy real. NVIDIA empuja la misma idea de memoria unificada hacia el escritorio con el DGX Spark: superchip GB10 Grace Blackwell, 128 GB de memoria unificada coherente a 273 GB/s, capaz de correr modelos de hasta 200B parametros localmente (specs oficiales NVIDIA). No tiene una GPU dedicada con VRAM separada en el sentido clasico, pero sale alrededor de USD 4.000. Lo mismo aplica a un Mac Studio bien equipado.
La conclusion practica: LMCache + memoria unificada te permite desarrollar y validar localmente sin la friccion (ni el costo de entrada) de una GPU NVIDIA dedicada. Pero llevar esto a escala, o tener un equipo con suficiente memoria unificada para modelos grandes, sigue siendo una inversion concreta.
Monta el entorno en diez minutos
1. Entorno de Python aislado
La API v1 del KV connector de vLLM requiere Python >= 3.11 (la guia original se probo con 3.12). Tambien necesitas cmake para compilar vLLM desde fuente.
mkdir -p ~/projects-test && cd ~/projects-test
# venv compartido (vLLM + LMCache lo usan juntos)
python3 -m venv .venv-lmcache
source .venv-lmcache/bin/activate
pip install -U pip wheel setuptools
2. Clona los repos
cd ~/projects-test
git clone https://github.com/vllm-project/vllm.git
git clone https://github.com/LMCache/LMCache.git
3. Instala vLLM para CPU
El wheel de PyPI viene compilado con CUDA, asi que importarlo en una laptop sin GPU falla. Para desarrollo del dia a dia conviene compilar desde fuente (te mantiene alineado con el codigo mas reciente):
cd ~/projects-test/vllm
source ~/projects-test/.venv-lmcache/bin/activate
pip install uv
VIRTUAL_ENV=~/projects-test/.venv-lmcache \
uv pip install -r requirements/cpu.txt --index-strategy unsafe-best-match
pip install setuptools_scm setuptools_rust
VIRTUAL_ENV=~/projects-test/.venv-lmcache VLLM_TARGET_DEVICE=cpu \
uv pip install -e . --no-build-isolation
Si solo queres validar el flujo rapido, existe el wheel vllm-cpu-nightly via el script .github/scripts/install_vllm_cpu.sh del repo de LMCache.
4. Instala LMCache con NO_GPU_EXT=1
Este es el punto clave en una laptop. Sin esa variable, pip install -e . intenta traer dependencias de GPU (cuda runtime, nixl, cupy) y compilar la extension CUDA, fallando de entrada.
source ~/projects-test/.venv-lmcache/bin/activate
# nvtx necesita Cython; en macOS instalalo a mano primero
pip install Cython openai
# Salta extensiones y dependencias de GPU, mantiene lmcache_fs / lmcache_redis
NO_GPU_EXT=1 pip install --no-build-isolation -e ~/projects-test/LMCache
Si al verificar ves "StubCPUDevice" o "Skipping backend lmcache.c_ops", el backend de CPU se activo correctamente.
Planifica la memoria (o vas a tener OOM)
OOM = Out Of Memory: el error que tira el sistema cuando un proceso pide mas memoria de la disponible y se cae.
Es la trampa mas comun al correr vLLM + LMCache en una laptop. Tenes que reservar memoria al mismo tiempo para el pool de KV de vLLM, la cache L1 de LMCache y el propio proceso de Python.
Configuracion recomendada para una MacBook de 16 GB:
- Pool KV de vLLM:
VLLM_CPU_KVCACHE_SPACE=1(1 GB, de sobra para opt-125m) - Cache L1 de LMCache:
--l1-size-gb 1
Si tu laptop tiene solo 8 GB: baja a VLLM_CPU_KVCACHE_SPACE=0.25, --l1-size-gb 0.5, y limita con --max-model-len 300 --max-num-seqs 1.
En macOS arm64, exporta esto antes de levantar vLLM para evitar un deadlock de OpenMP al iniciar:
export VLLM_CPU_OMP_THREADS_BIND=nobind
export OMP_NUM_THREADS=1
export KMP_BLOCKTIME=0
Verificacion rapida (sin vLLM)
Antes de ir al flujo completo, hay una forma mas liviana de validar: levantar solo el servidor de LMCache y correr el bench. No necesita vLLM ni descargar modelos, y el loop "cambio codigo -> verifico" es de menos de 20 segundos.
# Terminal: levanta el server
lmcache server --port 5555 --http-port 8080 --l1-size-gb 1 --eviction-policy LRU &
# Espera el healthcheck
while ! curl -fsS http://127.0.0.1:8080/healthcheck 2>/dev/null; do sleep 1; done
# Corre el bench
lmcache bench server \
--rpc-url tcp://127.0.0.1:5555 \
--url http://127.0.0.1:8080 \
--mode cpu \
--transfer-mode lmcache_driven \
--num-tokens 512 --end 3
Una corrida exitosa imprime "CHECKSUM MATCH OK" tres veces. Si ves "CHECKSUM MISMATCH", los datos se corrompieron en el store o el retrieve: tu cambio probablemente metio un bug. Es el chequeo minimo de salud antes de abrir un PR.
Tu primer end-to-end: vLLM CPU + LMCache
Con vLLM en la mezcla tenes un entorno completo y debuggeable de inferencia + reutilizacion de KV. vLLM corre en CPU y le pasa el KV al servidor de LMCache via el KV connector.
# Terminal A: server de LMCache
lmcache server --port 5555 --http-port 8080 --l1-size-gb 1 --eviction-policy LRU
# Terminal B: vLLM apuntando al connector de LMCache
export VLLM_CPU_OMP_THREADS_BIND=nobind OMP_NUM_THREADS=1 KMP_BLOCKTIME=0
export VLLM_DEVICE=cpu VLLM_CPU_KVCACHE_SPACE=1 VLLM_HOST_IP=127.0.0.1 GLOO_SOCKET_IFNAME=lo0
vllm serve facebook/opt-125m \
--port 18000 --dtype bfloat16 \
--disable-hybrid-kv-cache-manager --no-enable-prefix-caching \
--max-model-len 2048 --max-num-seqs 1 \
--kv-transfer-config '{
"kv_connector": "LMCacheMPConnector",
"kv_role": "kv_both",
"kv_connector_module_path": "lmcache.integration.vllm.lmcache_mp_connector",
"kv_connector_extra_config": {
"lmcache.mp.host": "tcp://localhost",
"lmcache.mp.port": 5555,
"lmcache.mp.mp_transfer_mode": "lmcache_driven"
}
}'
Importante: se apaga el prefix caching propio de vLLM (--no-enable-prefix-caching) y se le delega toda la responsabilidad de reutilizar KV a LMCache.
Como contribuir
Lo mejor de todo: no necesitas una GPU para empezar a aportar. Hay cuatro frentes donde podes trabajar desde tu laptop:
- Frontend
- L1 Eviction (politicas de desalojo en memoria)
- L2 Storage (disco, Redis, object storage)
- Observability
El flujo de PR es el clasico de open source: forkeas LMCache/LMCache, creas una branch siguiendo conventional commits (feat / fix / refactor / docs / test), configuras pre-commit (corre ruff, mypy, etc.), corres los tests del modulo y la validacion end-to-end local, y abres el PR explicando "problema / motivacion / solucion / como lo verificaste".
Un detalle del proyecto: al commitear, agrega el flag -s (git commit -s -m "...") para firmar con Signed-off-by. Es un requisito.
La propuesta del trabajo multiplataforma de LMCache es justamente esa: bajar la barrera de entrada para que cualquier persona, sin importar si tiene una GPU NVIDIA dedicada, pueda colaborar sobre el mismo codebase. No es que el hardware sea gratis (la memoria unificada y los equipos que la traen tienen un costo real), pero ya no necesitas una placa dedicada para empezar.
Si te interesa la infraestructura de inferencia de LLMs, este es un punto de entrada inmejorable para meter mano de verdad.
Este articulo es una adaptacion didactica al español de "vLLM + LMCache: A Starter Guide, No GPU Required" del LMCache Team. Te recomendamos leer el original para los detalles completos y los scripts de CI de referencia.
Artículos relacionados

Guía Práctica de Prompt Engineering
Técnicas avanzadas para escribir prompts que realmente funcionan. De principiante a experto en una guía.

Agentes de IA que Escriben Codigo: El Estado Real en 2026
De Copilot a agentes autonomos: que pueden hacer realmente, donde fallan, y como esta cambiando el desarrollo de software.

El Futuro de la IA Multimodal
Cómo la visión, el lenguaje y el razonamiento están convergiendo en una nueva era de inteligencia artificial que lo cambia todo.